| N° | Project | Description | Area | Year | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 32 | Marimo | Open-source contributions to a reactive Jupyter notebook alternative | Data science | 2024 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Marimo is an open-source reactive notebook for Python. Traditional Jupyter notebooks have a hidden state which often leads to incoherence among cell states and reproducibility issues. Marimo solves this problem by representing the notebook as a directed acyclic graph which allows for reactively updating any downstream dependencies. 
This is the first major open-source project that I have contributed to. There is an incredible learning factor to it as the project is actively maintained and people constantly review and constructively criticise every pull-request. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 31 | Lex | NLP tool for exhaustive and context-driven vocabulary acquisition | Natural language processing | 2023-2024 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Recently I made an observation on attentional bias when encountering new words: after being presented with a new word for the first time, I see it everywhere from that point on, including in the books that I read. Usually I unconsciously memorise the sentence it appears in, which helps me tremendously remembering its meaning in the long-term. Lex is an NLP tool which was developed around this observation. Its goal is to facilitate exhaustive vocabulary acquisition. Given a new book that I’m about to read, Lex selects all words that I do not know yet by referring to a reference vocabulary. It then contextualises them, i.e. for every new word it finds the surrounding context. This allows me to learn new words before reading a book. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 30 | Neural machine translation | Implementation of two NMT models from scratch | Natural language processing | 2024 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
This project focused on implementing and training two models for neural machine translation from scratch: the lexical attention model as described in Nguyen and Chiang (2017) and a basic implementation of the Transformer architecture and the multi-head attention mechanism according to Vaswani et al. (2017). The models were trained on German-to-English data. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 29 | Number agreement prediction | Using an RNN to predict number agreement between subject and predicate | Natural language processing | 2024 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
This project focused on learning how to take models proposed in research papers, often represented by 5-10 equations, and putting them into use for a simple downstream task. The form of the English predicate depends on the subject of the sentence. “The pen are on the desk” is incorrect, there is no number agreement. The task is to have a model predict the predicate form (singular [VBZ] or plural [VBP]) based on all words preceding the predicate. This project involved the implementation and training of two models. Recurrent neural networks (RNNs) are inherently well-suited for this task due to their ability to learn long-range dependencies. As they suffer from the vanishing gradient problem, the Gated Recurrent Unit (GRU) variant was implemented for comparison. The models were adjusted for the agreement task and trained on a small set of training data in the following form:
Back-propagation-through-time was used for training, with varying lookback values. The results were promising given the limited amount of data used for training:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 28 | Deep RL experiments | Implementation of deep RL algorithms using OpenAI’s gym | Reinforcement learning | 2024 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
This project implemented various RL algorithms from scratch using OpenAI’s gym environment for training and evaluation of agents.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 27 | Linux kernel experimentation | Three small experiments involving the Linux kernel | Systems programming | 2024 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
This project was part of a recurring University
course and its codebase can thus not be published. Please contact me if
you are interested in further details about its implementation. The first experiment focused on implementing a custom aging scheduling policy, a scheduling technique where there is an increase in priority as a process is waiting for runtime. This is used to avoid starvation among processes. The second part involved experimentation with the memory subsystem of Linux. First a shared memory kernel module was implemented to facilitate shared memory usage among different user application. This was achieved by using a character device and memory mapping. In the second step, a custom memory analyser collects and prints various memory statistics in the following format: The third experiment involved manipulating filesystem
functionalities. First a read censor was implemented, censoring certain
strings present in a file upon read if it was tagged with a special xattr key.
Second, filtering functionality for the output of running
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 26 | Eric Janto website redesign #3 | Redesign and reimplementation of a personal website | Web development | 2024 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Website redesign for ericjanto.com with a focus on minimalism and a brutalist, text-only and monochrome presentation. This involved extensive research into table design beforehand, collected in an are.na channel. One of the main benefits is that it allows for
extensive use of marginalia. 
This is the first year no framework was used for the implementation. A custom static-site generator was built with a single dependency on Pandoc to convert Markdown to HTML. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 25 | Bookmarks landing page | Lightweight browser landing page for displaying bookmarks | Web development | 2024 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 24 | Interactive lecture videos | Integration of spaced-repetition into interactive lecture videos | Web development | 2023 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 23 | Part-of-speech tagger | Implementation of a Hidden-Markov-Model for part-of-speech tagging | Natural language processing | 2023 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 22 | Language classification | Implementation of an Lgram model to identify English text | Natural language processing | 2023 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 21 | Generative music | MaxMSP project to generate music from natural language instructions | Creative coding | 2023 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 20 | Story Hunter | An improved search engine for the AOC3 platform | Data engineering | 2023 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
This project was part of a recurring University
course and its codebase can thus not be published. Please contact me if
you are interested in further details about its implementation. The priority was to allow for fast look-up times of ranked documents given the user query. This was achieved by using a positional inverted index along with td-idf ranking. 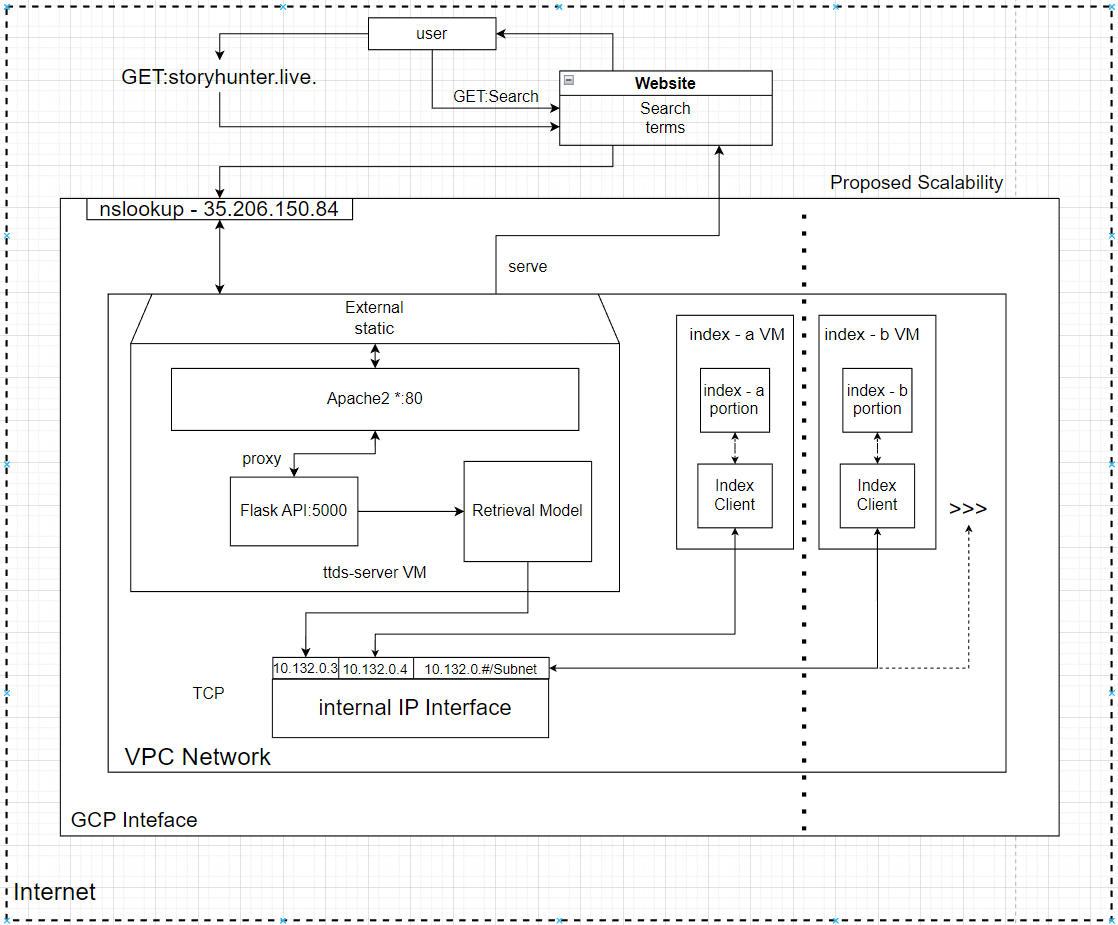
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 19 | Human Cadherin-7 analysis | Sequence retrieval and analysis of Human Cadherin-7 analysis | Bioinformatics | 2023 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 18 | Gene-disease mapping data exploration | Comparison of the genetic basis of neural and digestive system disorders | Bioinformatics | 2023 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 17 | Mac setup | Script for the automated setup of MacOS-based machines | Scripting | 2023 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 16 | Name variations | Implementation and visualisation of a name variation algorithm | Natural language processing | 2022 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 15 | Cargo vessel routing optimiser | Optimiser for cargo-loading and routing logistics based on AIS (Automatic Identification System) data | Data science | 2022 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 14 | Bionic Markdown | NPM module for producing Markdown conforming to Bionic Reading standards | Web development | 2022 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 13 | Wikipedia ctrl+k menu | A tool for summarising and explaining Wikipedia articles with ChatGPT | Web development | 2022 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 12 | Web watch | Tool to get notified about changes made to third-party websites | Scripting | 2022 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 11 | Frontmatter processor | NPM module to manipulate metadata fields in Markdown files | Web development | 2022 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 10 | Eric Janto website redesign #2 | Redesign and reimplementation of a personal website | Web development | 2022 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9 | Note publishing website | Front-end for publishing academic Markdown notes | Web development | 2021 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 8 | Sliding window protocol | Implementation and analysis of the sliding window protocol | Networks | 2021 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 7 | Booking automation | Selenium-based tool to automatically book swim session slots | Scripting | 2021 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6 | MIPS simulator | 5-stage multi-cycle processor simulator for the MIPS assembly language | Systems programming | 2021 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 5 | EUJO website | Website design and implementation for the Edinburgh University Jazz Orchestra | Web development | 2021 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4 | Eric Janto website redesign #1 | Redesign and reimplementation of a personal website | Web development | 2021 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 3 | Corona-Warn-App | Smoke-testing of UI prototypes for Germany’s official COVID-19 app | Software testing | 2020 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2 | EUSO website | Website design and implementation for the Edinburgh University String Orchestra | Web development | 2020 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | Eric Janto website | Initial implementation of a personal website | Web development | 2020 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Not filed yet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||